The System Around the Model: Building an AI Behavior & Context Architecture Framework

I have been asked many versions of the same question: how do we prompt the AI so it behaves the way we want?
It is a reasonable question. The prompt is the visible surface. It is the part people can read, edit, argue with, and quickly improve. But prompting alone is too narrow for systems that need reliable behavior inside workflows.
The Model Is Not The System
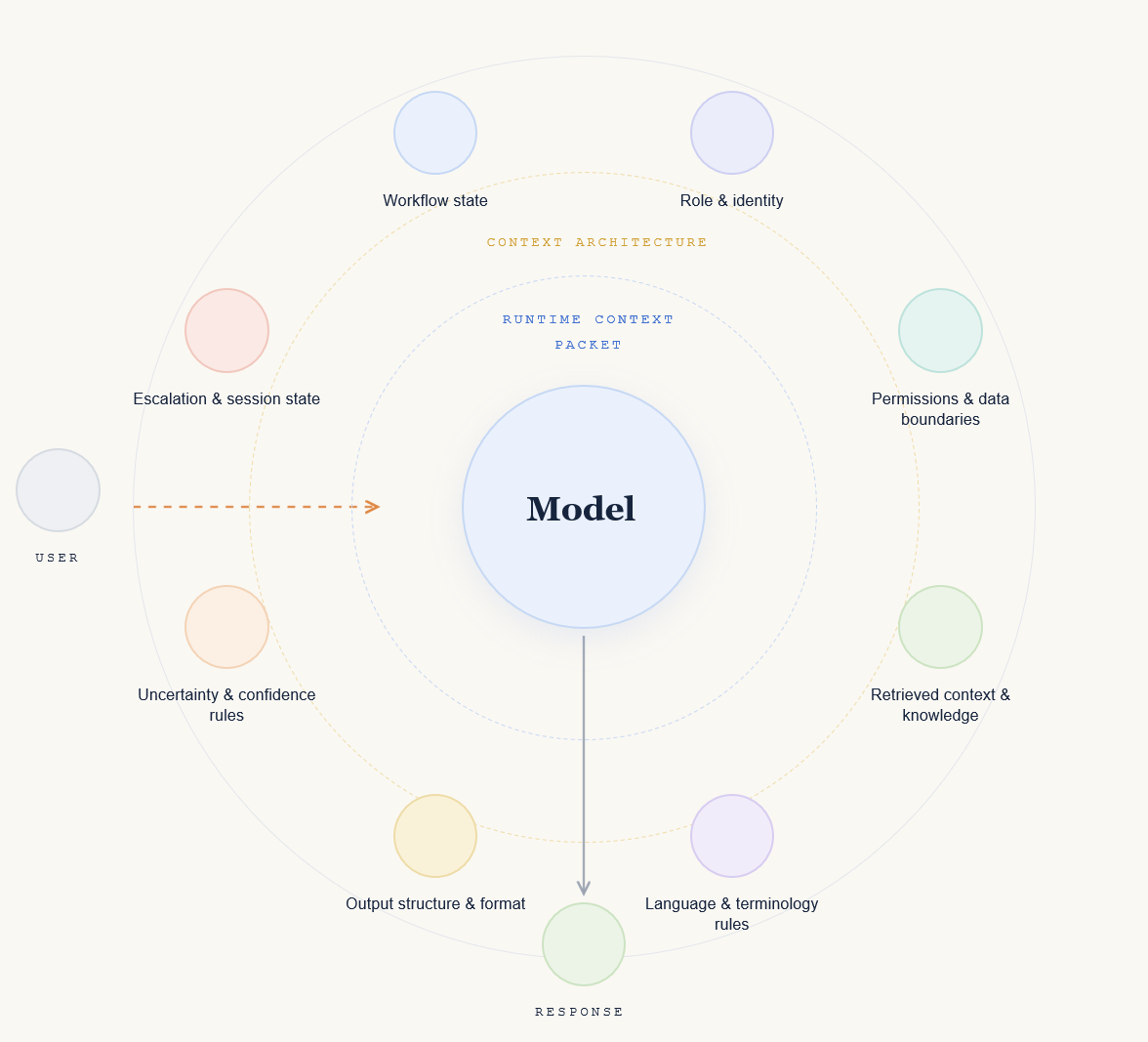
A model’s behavior is shaped by the system around it:
what context it receives
what context it can retrieve
what workflow state it can see
what user role it is responding to
what data boundaries apply
what language rules are active
what output structure is expected
what uncertainty it is allowed to surface
what it should do when information is missing
how the interaction recovers after interruption
Once those conditions matter, the design problem changes. The work becomes behavioral architecture.
The system needs to define the operating conditions that shape the model’s response before the model is asked to produce one. That is the purpose of an AI Behavior & Context Architecture Framework: to make the system around the model explicit enough to design, test, review, and improve.
---
The Missing Layer
Visible interface decisions are useful as starting points for AI initiatives, but they rarely define enough of the operating environment.
There Is A Layer Almost Nobody Designs On Purpose
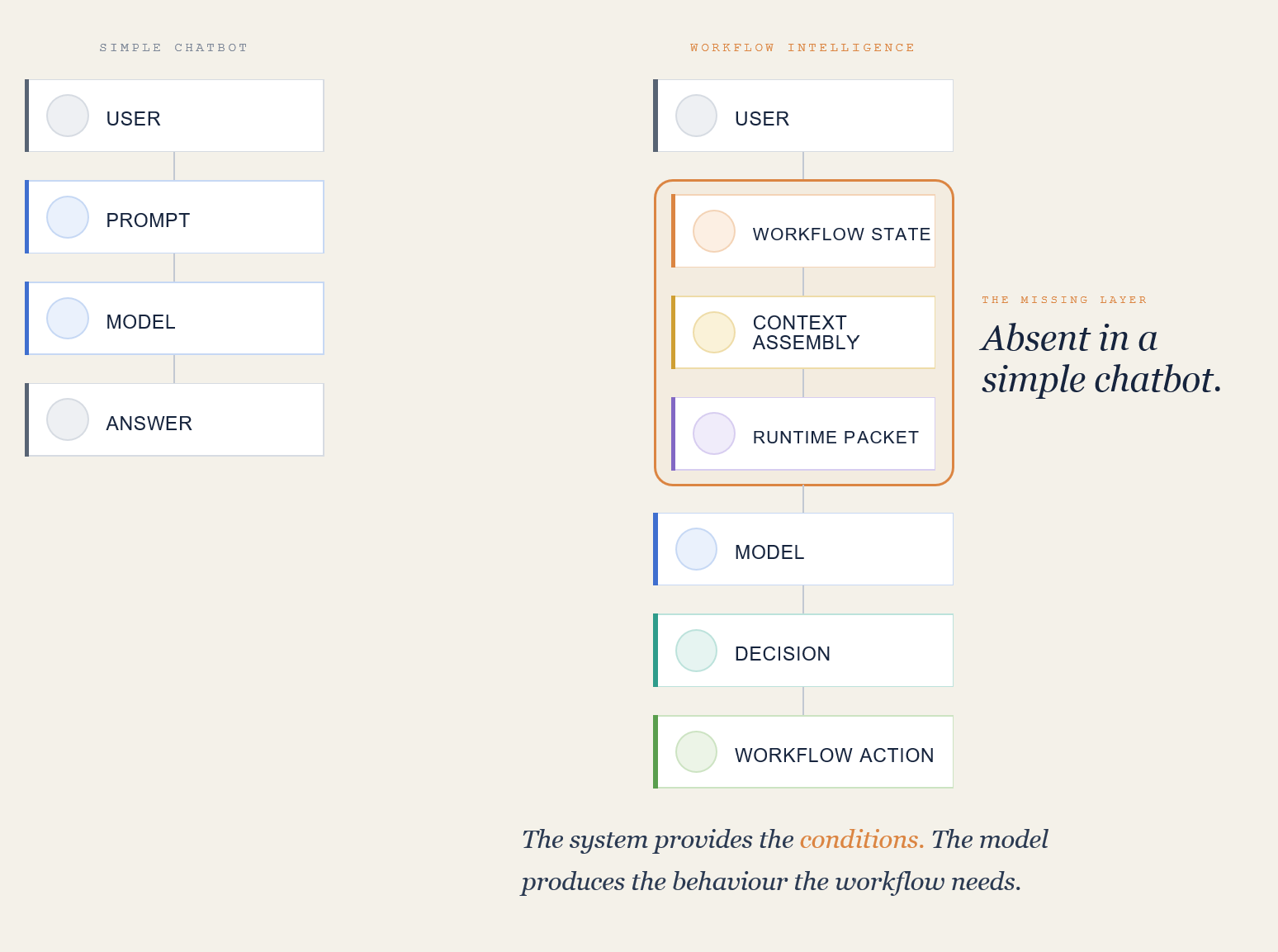
A workflow-aware AI system may need to understand:
where the user is in the process
what has already happened in the current session
what information is known, missing, inferred, or retrieved
which records are relevant to the current task
which records the user is allowed to see
how similar cases should be compared
when the assistant should ask a question
when it should make a safe inference
when it should prepare a structured output
when it should stop and escalate
Those decisions shape behavior more than wording alone. A prompt can describe desired behavior. A context architecture gives the model the conditions required to perform that behavior inside the workflow.
The practical question then becomes:
What does the model need to know, at this moment, to behave correctly?
That question should be answered by the system, not improvised inside the model response.
---
Prompting Has to Sit Inside Runtime Architecture
Prompts are instructions. Workflows are stateful operating environments.
A prompt can define tone, role, constraints, and output expectations. It can also encode behavioral guidance. That work still matters.
Runtime architecture defines what the model receives when it is asked to act.
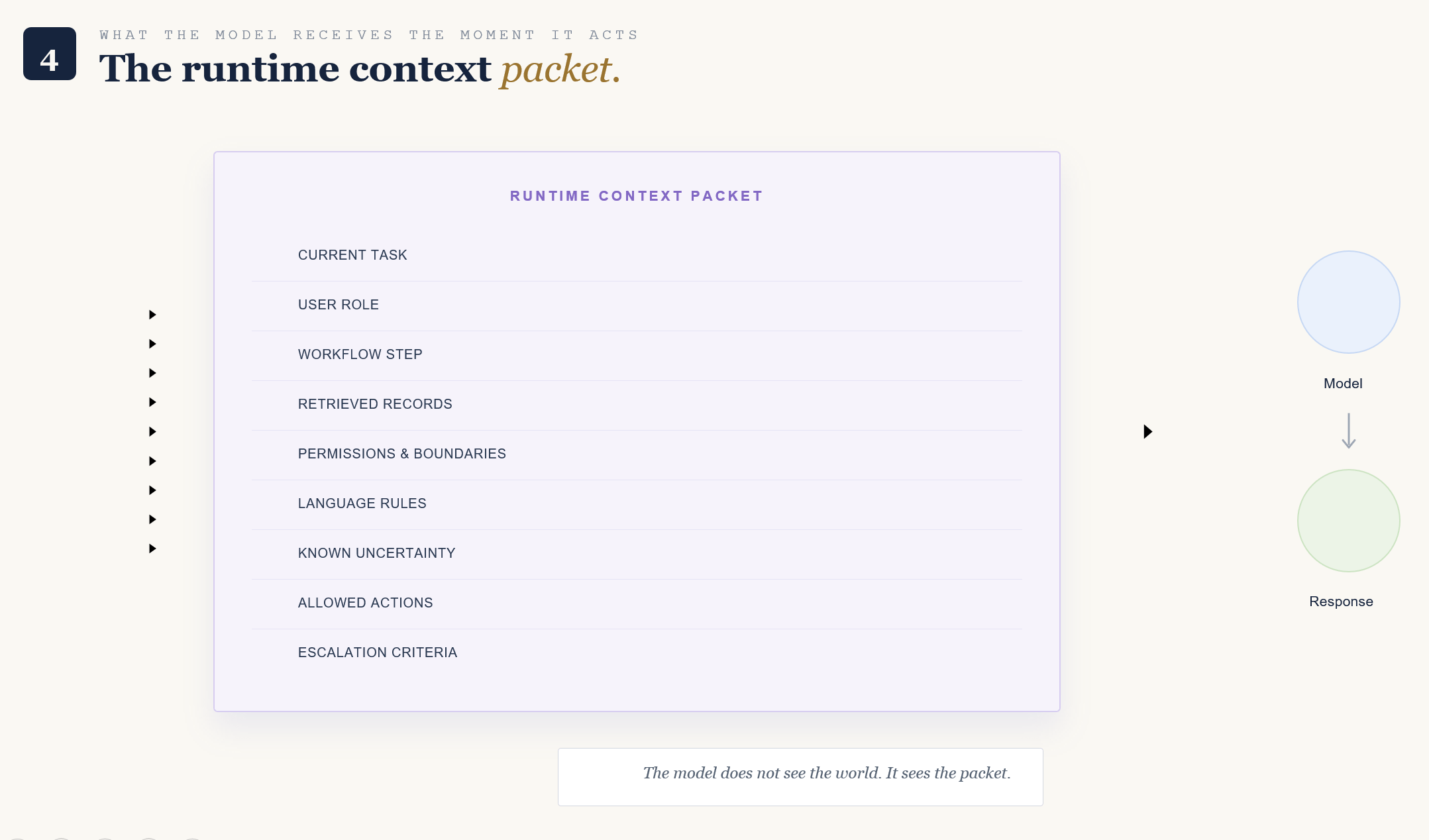
In a workflow, the model may need a structured packet containing:
the current task
the user’s role
the workflow step
prior session state
retrieved records
unavailable or restricted data
language handling rules
output schema
known uncertainty
allowed actions
escalation criteria
This packet becomes the model’s operating frame for that moment.
Without this frame, the model is left to infer too much from the user message and whatever static instruction was provided. That can produce acceptable answers in simple interactions and unstable behavior in complex workflows.
With a runtime context packet, teams can decide what gets included, what gets excluded, what gets prioritized, and what the model should do with each type of context. The prompt still exists. It just carries less unsupported weight.
---
From Chat Interface to Workflow Intelligence
A chat interface can respond to messages. A workflow intelligence layer participates in a process.
That participation requires awareness of task state. The system has to know whether the user is exploring, drafting, reviewing, editing, comparing, approving, submitting, or recovering from an interruption. Each state changes what context matters.
For example, in a public service request and feedback workflow, the assistant may help a resident, business owner, or internal service team describe a question, issue, complaint, feedback item, or service request. The same workflow may also require the system to:
identify missing information
distinguish between a question, complaint, service request, issue report, or feedback item
preserve the user’s original intent
classify the request by service category
check whether related case history is available and permitted
prepare a structured case record
route the case to the appropriate service team
The same need applies to summarization, classification, translation, drafting, recommendations, and decision support. AI capabilities become more useful when the workflow defines the conditions for their use.
---
A Practical Framework Structure
A behavior and context architecture framework should make the system reviewable in layers.

Each folder contains documentation that answer different kinds of system question:
00-system-overview
This layer defines the purpose of the AI system and the principles that guide its behavior.
Example document:
AI Design Principles
This document should define operational principles that can guide design, implementation, and testing.
Useful principles might include:
Reduce user effort while keeping important decisions visible.
Ask fewer, better questions.
Preserve user intent when restructuring content.
Separate known facts, retrieved information, inferred context, and uncertainty.
Protect restricted information even when disclosure would make the interaction feel more convenient.
A principle becomes useful when it can be tested against behavior.
01-behavioral-specifications
This layer defines how the AI should behave in specific roles or workflows.
Example documents:
AI Assistant Behavior Spec
Public Service Request & Feedback Triage Assistant Behavior Spec
A behavior spec should define:
the assistant’s responsibilities
the boundaries of the assistant’s role
when it should ask questions
when it should infer
when it should retrieve
when it should escalate
how it should handle incomplete input
how it should preserve user intent
how it should prepare structured outputs
For a public service request and feedback triage assistant, the behavior spec might include:
help users describe incomplete or unclear requests
distinguish between questions, complaints, feedback, issue reports, and service requests
preserve the user’s original intent before restructuring the case
ask only for missing information that affects routing, eligibility, urgency, or service resolution
check related case history only when the user is permitted to access it
explain routing or escalation decisions clearly
prepare structured outputs for service teams or reviewers
This is behavior architecture. The system is defining how the assistant should act before those expectations are compressed into prompts, flows, or code.
02-context-architecture
This is the core operational layer.

Example documents:
Context Architecture Spec
Runtime Context Template
Context Assembly Rules
Language Handling Rules
Service Category Routing Rules
Case History Context Rules
Example Context Packets
This layer defines what context exists, where it comes from, when it is included, how it is prioritized, and how it should be interpreted.
It should answer questions such as:
What context is always included?
What context depends on user role?
What context depends on workflow step
What context is retrieved dynamically?
What context is inferred from the current session?
What context is restricted from model access
How are conflicts handled?
How are multilingual inputs handled?
What structured format does the model receive?
How should context be labeled so the model understands its source and status?
This layer turns context assembly into a design decision instead of an accidental side effect of implementation.

03-testing-diagnostics
This layer defines how the AI system will be tested and diagnosed.
Example document:
Testing & Diagnostics Spec
AI systems need tests for behavior, reasoning, retrieval use, language handling, permissions, and workflow fit.
A weak test asks:
Was this answer good?
A stronger test asks:
Did the system behave correctly given the context it received?
The second question makes failures easier to diagnose because it connects output quality to system conditions.
04-sd-ux-workflow
This layer connects AI behavior to the user experience.
Example document:
Public Service Request & Feedback Conversation Flows
It defines how the AI interaction appears to the user across the workflow
It should include:
entry points
conversation stages
question patterns
interruption paths
review moments
confirmation moments
handoff points
recovery flows
structured output moments
This layer should always be aligned with the behavior and context layers
If the interface asks the assistant to do something the context architecture does not support, the system will drift. If the context architecture supports a capability the UX never exposes, the value stays hidden.

---
Runtime Context Architecture
Runtime context architecture defines what the model knows at the moment it is asked to act.
That context can come from several sources.
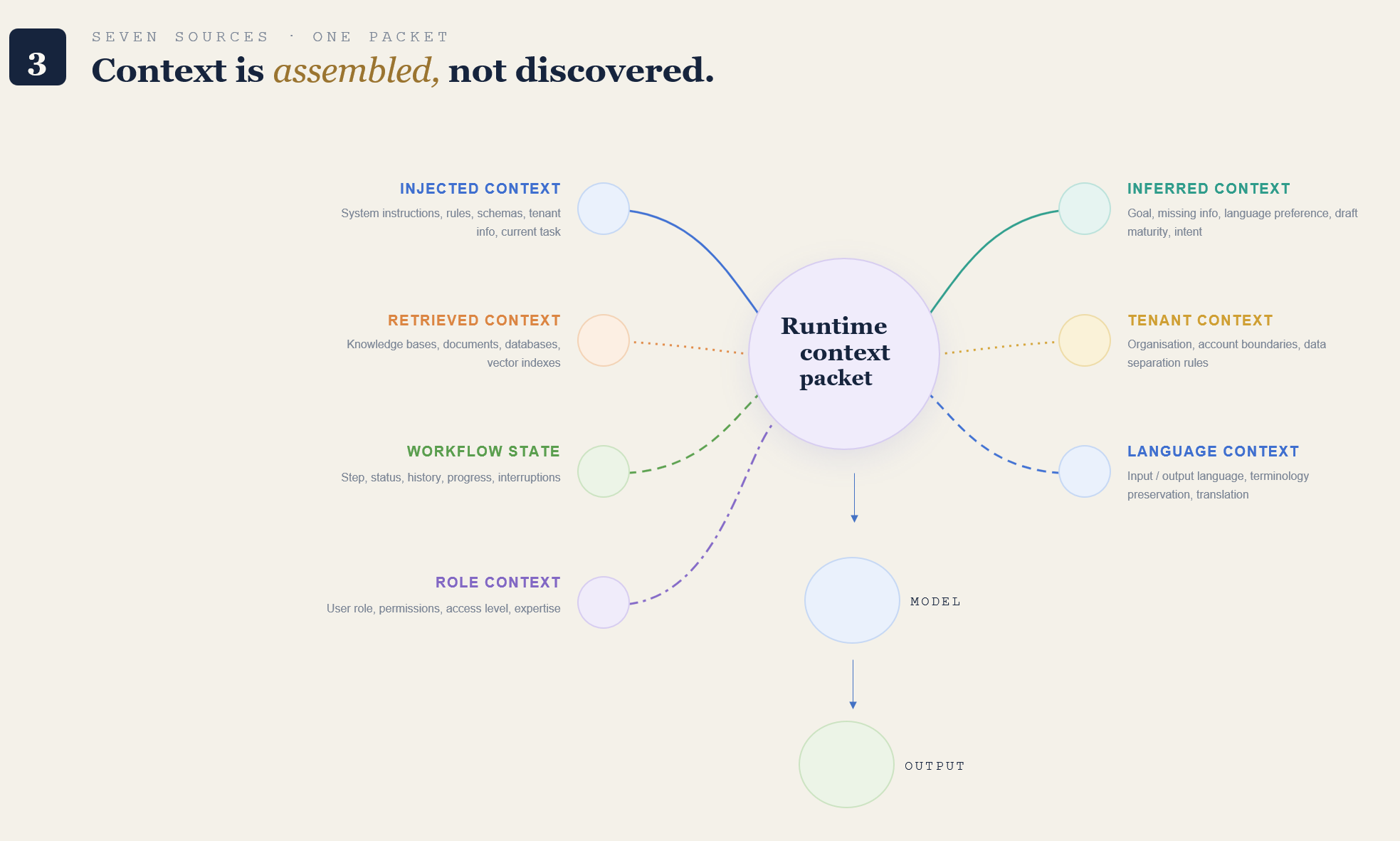
Injected context
Context deliberately passed into the model by the system.
This may include system instructions, workflow rules, output schemas, tenant information, user role, and current task state.
Inferred context
Context derived from the current interaction.
This may include the user’s likely goal, missing information, language preference, draft maturity, or whether the user is exploring versus finalizing.
Inferred context should be labeled carefully. It can improve usefulness and create false confidence when the system treats inference as fact.
Retrieved context
Context pulled from a knowledge base, database, document store, vector index, or other source.
Retrieved context needs governance. The system should define what can be retrieved, how relevance is determined, what metadata matters, and how the model should use retrieved material.
Workflow-state context
Context about where the user is in the process.
A user asking a service question needs different support than someone filing a complaint. A resident following up on an existing case needs different context than a service team reviewing a routed request.
Role context
Context about who the user is in the system.
Different roles may require different levels of explanation, different allowed actions, and different visibility into records.
Tenant context
Context about organizational or account boundaries.
This is especially important in multi-tenant systems where retrieval must respect data separation.
Language context
Context about input language, output language, translation rules, terminology preservation, and multilingual retrieval behavior.
Language handling should be specified when the system operates across languages. The system needs rules for preserving original phrasing, translating content, summarizing across languages, and asking for confirmation when meaning may change.
All of these context types need assembly rules.
Context assembly rules define how the system decides what to include, exclude, prioritize, compress, label, and pass into the model.
We already know that AI behavior quality depends heavily on context quality. A capable model given messy context may behave inconsistently. A smaller model given well-structured context may behave more predictably than expected. The model matters, but the operating conditions matter too.
---
Testing & Diagnostics

AI systems need QA architecture. “Sounds good” is not a QA methodology.
A production AI system should be tested for behavior across realistic scenarios and failure modes.

Important diagnostic categories include:
Reasoning behavior
Does the system distinguish between known facts, retrieved information, inferred context, and uncertainty?
Does it explain reasoning when useful and stay concise when the task is simple?
Workflow drift
Does the assistant stay aligned to the current workflow step?
Does it understand whether the user is drafting, reviewing, editing, submitting, or comparing?
Retrieval misuse
Does the model use retrieved context appropriately?
Does it over-weight irrelevant retrieved content because it appears in the packet?
Does it ignore important retrieved content because the user phrased the request differently?
Over-questioning
Does the assistant ask for information already available in the context?
Does it ask technically reasonable questions that do not improve the current workflow outcome? (Good AI interaction often depends on asking fewer, better questions.)
Hallucinations
Does the assistant introduce information absent from the user input, retrieved context, or allowed system knowledge?
Does it fabricate workflow rules, case details, routing logic, or escalation explanations?
Language instability
Does behavior change when the user switches languages?
Does the assistant preserve meaning across multilingual input?
Does it translate terms that should remain unchanged?
Permission leakage
Does the assistant expose information the user should not see?
Does it reveal restricted records through summaries, similarity explanations, or indirect references?
False related-case matches
Does the system flag unrelated records as related cases?
Does it miss relevant case history because the wording differs?
Does it explain the basis for related-case detection in a way the user can evaluate?
These tests should connect to the context architecture. Then when a failure occurs, the team should be able to ask:
Did the prompt fail?
Did retrieval fail?
Did packet assembly fail?
Did permission logic fail?
Did workflow state fail?
Did the model ignore or misuse available context?
The goal is layer-level diagnosis.
---
One Important Last Thought: Human Review Does Not Scale Cleanly
As AI systems become more operational, their documentation becomes harder to review manually.
A mature behavior and context architecture may include:
behavioral specs
system principles
context templates
retrieval rules
workflow flows
language rules
similarity rules
test scenarios
diagnostic categories
runtime packet examples
permission rules
escalation conditions
Each document may be clear in isolation. But they need to work together.
Review needs to catch issues such as:
behavior specs that conflict with UX flows
context assembly rules that do not support the intended behavior
testing scenarios that miss the documented risk areas
language rules that conflict with retrieval behavior
permission rules that fail inside related-case explanations
runtime packets that include context without enough source labeling
review flows that depend on information the system never receives
These become architectural consistency problems. Dense AI documentation needs review formats that make dependencies visible.
AI-mediated review layers can help convert system documentation into formats humans can actually inspect.
For example, AI review layers could:
turn architecture docs into stakeholder-specific discussion guides
flag contradictions between behavior specs and context rules
identify missing test scenarios
summarize runtime logic for product, engineering, legal, or operations teams
generate plain-language walkthroughs for review sessions
compare example context packets against assembly rules
check whether UX flows are supported by available context
detect where permission leakage may occur
This keeps human responsibility where it belongs: judgment, decision-making, and accountability. AI can help expose the parts of the system that need that judgment.
This may lead to stable review agents configured to understand the architecture, check for contradictions, and help teams evaluate changes over time.
The goal is practical: make dense AI architecture more reviewable, traceable, and discussable. If AI systems require layered documentation, the review process needs layered support.
---
Practical Guidance for Product and Engineering Teams
Teams building AI-enabled workflows should define the system around the model before relying on model behavior.
Useful questions to get started:
What should the assistant do in this workflow?
What context does it need? Where does that context come from?
What depends on workflow state?
What depends on user role?
How should uncertainty be handled?
How should the system recover after interruption?
How should behavior be tested?
How should humans review the architecture?
These are architecture questions.
For developers and technical product teams, the AI layer becomes a runtime participant in the product architecture.
For UX and system designers, the work expands into conversational behavior, context availability, workflow continuity, and failure recovery.
For enterprise teams, governance belongs inside the operating structure: permissioning, retrieval boundaries, diagnostics, and review processes.
The model should receive the conditions required to behave well. Those conditions have to be designed.
---
In Closing: The System Around the Model
The next phase of AI system design is about operating environments for models. Prompting remains part of the work. Behavior architecture, context architecture, runtime orchestration, diagnostics, and review systems determine whether the AI can function reliably inside an actual workflow.
AI systems are judged by repeated behavior under changing conditions:
different users
incomplete information
shifting workflow states
multilingual input
retrieved context
permission boundaries
interruptions
edge cases
The model is important. But the system around the model determines what the model can reliably do.
That system defines what the model knows, what it can access, what it should avoid, how it recovers, how it is tested, and how humans can evaluate its behavior once it is live.
That is the work.
Templates and sample context architecture documentation here: GitHub
---
Thanks for responding to the meta‑level post — that already tells me you’re operating above the prompt‑and‑output layer. Most people stay inside the model’s behaviour; very few work on the structures that govern behaviour. If you’re dealing with things like state‑aware boundaries, context‑gating rules, or workflow‑level invariants, then you’re already in the territory I’m mapping.The article here makes a good point about the system around the model shaping behaviour, but the meta‑layer goes one step further: it’s where you define the rules that govern the system itself. That’s the layer where coherence, constraint, and stability are engineered, not prompted. If that’s the space you’re working in, then we’re speaking the same language.Happy to compare notes if you’re genuinely operating at that altitude — the meta‑level is a small room, and it’s rare to meet someone else who’s actually in it.🙂
Love this detailed breakdown of how to think about the complexity of context architecture, beyond the "put it in a prompt" or "just give an agent memory" (whatever that means 🙄).
This is a rapidly evolving area and it's refreshing to read a breakdown of it that treats it both as a technical problem and as a craft.
But the million dollar question: How do we manage all this at scale?
Databases are terrible because they obscure the prompts from your coding agents (unless you go through all the work to set up API connection to the data) and make versioning & audit is more tedious.
Git-managed .md file trees -- like the one linked in this post -- seem the only workable solution right now, but introduce their own management headaches after just 2-3 agents of even medium complexity.
Any better solutions here?